Seamless Gait Transition via Optimal Control & Reinforcement Learning
Quadruped Locomotion Research
Role: Algorithm Design & Evaluation • Tools: Python, RL Frameworks, Trajectory Optimization

Problem / Motivation
Quadruped robots often need to switch between different gaits (walk, trot, bound) to adapt to varying terrain and speed requirements. Traditional gait scheduling using heuristic state machines can produce abrupt transitions, leading to poor tracking, high energy consumption, or even loss of balance. This project aimed to design a controller that produces smooth, dynamically consistent gait transitions while maintaining robustness to modeling errors.
Idea & Methodology
- Used model-based trajectory optimization to generate feasible gait patterns (e.g., walking, trotting) that satisfy the robot’s dynamics and contact constraints.
- Represented each gait as a motion primitive and designed a parameterization that allows continuous interpolation between primitives in the state space.
- Trained a reinforcement learning policy to track these references while minimizing tracking error, control effort, and foot slip, using domain randomization to improve robustness.
- Implemented a transition scheduler that selects and blends motion primitives based on desired speed and terrain context.
Results / Evidence
In simulation, the combined optimal control and RL controller produced noticeably smoother transitions between walking, trotting, and faster gaits compared to a fixed, heuristic state machine. Center-of-mass tracking error and body pitch oscillations were reduced during transitions, and ground reaction forces remained within reasonable bounds.
The learned policy generalized to moderate variations in mass distribution and small height changes in the terrain without re-tuning, suggesting that the approach is promising for sim-to-real transfer on physical quadruped platforms.
My Contribution
- Implemented the dynamics interface between the quadruped model and the trajectory optimizer / RL environment.
- Designed the reward function to trade off tracking accuracy, energy usage, and contact stability.
- Conducted ablation studies comparing pure RL, pure trajectory tracking, and the combined approach.
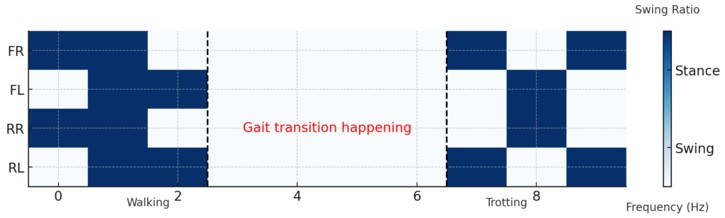
- Generated visualizations (phase plots, body motion snapshots, contact sequences) to analyze how the controller blended different gait primitives over time.
Artifacts
- Simulation videos showing transitions between multiple gaits.
- Python code for trajectory optimization and RL training environment.
- Slides and a short technical write-up summarizing the methodology and findings.